
Par Antoine Pemeja et Romuald Ribas,
Relecture par Sylvain Wallez (Elastic).
Le contexte
Au moment où notre client [Nom confidentiel] (top 3 des opérateurs télécom d’Afrique avec plus de 600 000 abonnés) décide d’anticiper la disruption du marché des télécoms dans son pays, ce dernier lance une plateforme 100% numérique. Premier dispositif entièrement pensé sans point de vente physique, l’enjeu est de taille pour l’Afrique.
L’objectif est simple: proposer une nouvelle offre par une expérience inédite et entièrement dématérialisée au travers un site internet, une web app et des applications mobiles iOS et Android.
L’organisation des équipes
Pour réaliser ce projet au périmètre fonctionnel ambitieux et cela dans un planning serré, Appstud a mis en place 3 équipes agiles de 4, 5 et 6 ingénieurs :
- 1 Scrum Master
Pour les frontaux mobiles:
- 3 développeurs iOS
- 3 développeurs Android
Pour le back end:
- 3 développeurs Backend (un architecte et 2 développeurs)
- 1 développeur API
Pour les frontaux web:
- 3 développeurs WebApp
- 2 développeurs Drupal
Kick Off Projet
Lorsque nous endossons la responsabilité d’un projet, il est important pour nous de comprendre l’ensemble des enjeux du Métier. Ainsi, le kick off s’est déroulé sur le site de notre client avec les équipes de développement d’AppStud. Chaque métier a pu présenter ses processus et ses besoins pour cette nouvelle marque. L’occasion pour nous de pleinement intégrer le métier d’un opérateur télécom qui s’articule autour de 5 axes:
- E-Commerce & Supply chain
- e-boutique
- configuration
- catalogue
- order management
- suivi de la commande
- livraison
- paiement et facturation
- Social & customer management
- customer information management
- selfcare
- customer service
- social
- Analytics & marketing
- digital marketing
- customer insights
- next best action
- Business mediation
- gestion des balances
- provisionning telco
- provisionning partenaires
- Operations support
- Alertes sur les usages
Définition de l’architecture technique
Nos équipes techniques ont commencé par rédiger un DAT (document d’architecture technique). Ce document couvre les points techniques du projet en s’adressant principalement :
- aux architectes et responsables techniques des projets du côté client,
- aux équipes d’intégration participant à la mise en place des systèmes,
- aux services en charge de l’exploitation du côté client.
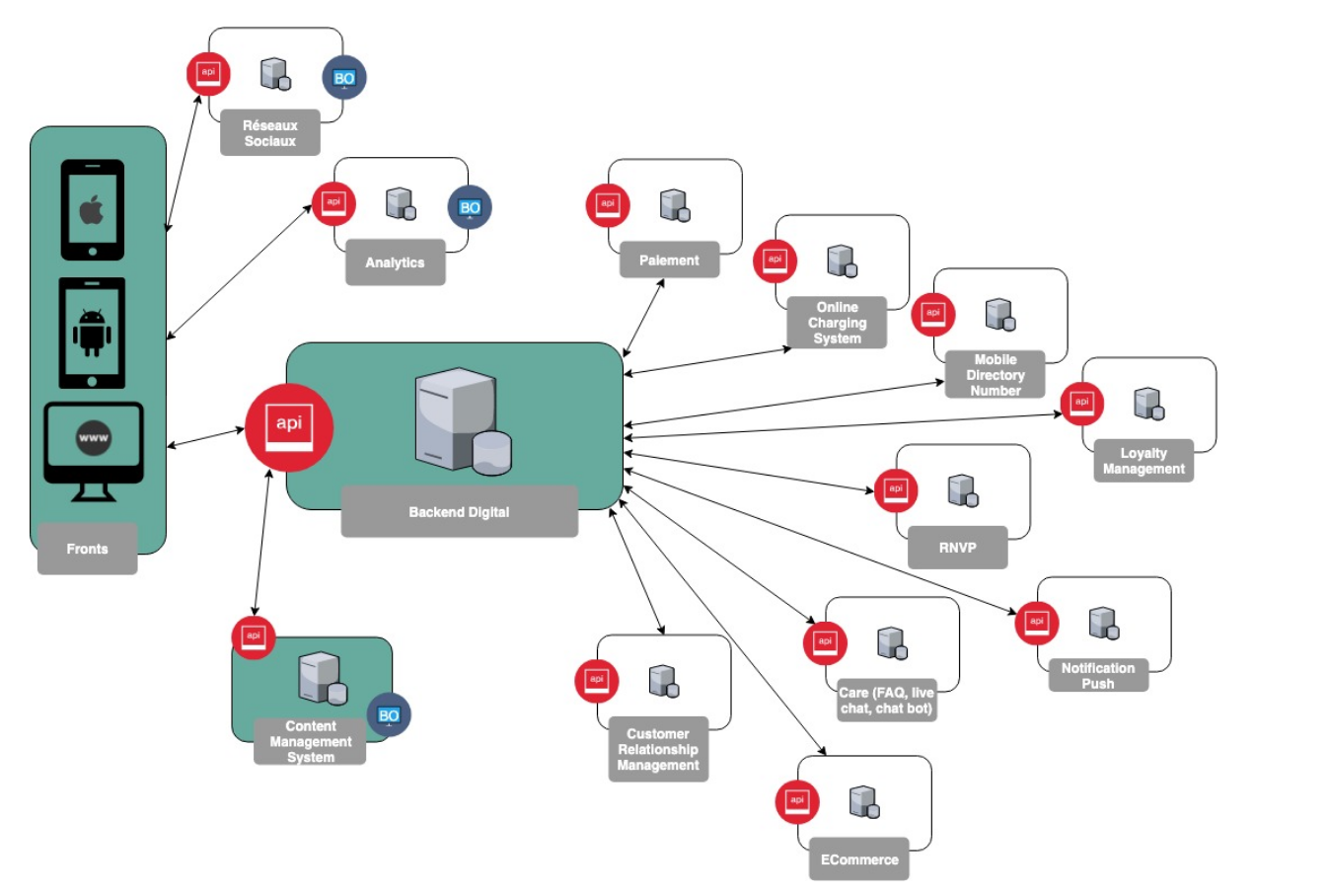
Fig 1. Macro Architecture technique
Commencer par la définition de l’architecture logique globale nous a permis de cartographier les composants logiques utilisés :
L’objectif était de découpler la partie présentation client (applications, site web) des processus et des données métiers. Cette séparation a été assurée par le composant Backend Digital qui est responsable de la transformation et de l’agrégation des données métiers issues de sources hétérogènes pour qu’elles soient restituées aux applications clientes (applications mobile, site web).
Les composants logiques identifiés :
- Backend Digital (API)
- L’application iOS
- L’application Android
- La WebApp
- Le Content Management System (CMS)
- L’analytique
- Les réseaux sociaux comme Facebook et Google pour se connecter.
- Customer Relationship Management (CRM)
- ECommerce pour récupérer le catalogue et créer les commandes
- Care pour récupérer la FAQ, proposer un live chat avec un chat bot et permettre de créer des “cases”.
- Loyalty Management pour gérer la fidélisation
- Le paiement
- Les push notification
- Le Online Charging System (OCS) pour gérer les consommations et les balances
- Le Mobile Directory Number (MDN) pour gérer les numéros de téléphone
- Le RNVP pour valider les adresses postales
L’intervention d’Appstud concernait le développement, la configuration et l’installation des composants suivants (fond vert sur le schéma) :
- Backend Digital (API)
- L’application iOS
- L’application Android
- La WebApp
- Le Content Management System (CMS Drupal) qui sera utilisé comme back office.
Chaque composant sera détaillé dans la DAT mais intéressons nous aux composants sous notre responsabilité dans cet article.
Le Back end Digital
Ce backend digital est responsable de la transformation et de l’agrégation des données issues de sources hétérogènes. Elles (les données) sont ensuite restituées via une API RESTful pour les applications clientes (applications mobile, site web). Ce backend digital laisse également la possibilité de rajouter les fonctionnalités et services non portés par les autres services externes. Il a été développé en langage Kotlin basé sur Java 8 et a utilisé le framework Spring Boot (https://projects.spring.io/spring-boot/) .

Fig 2: Organisation du back end digital
Pour rappel, le backend digital expose un SSO (Single Sign-On : https://fr.wikipedia.org/wiki/Authentification_unique) qui sert de point d’entrée aux utilisateurs souhaitant accéder aux APIs RESTful (format d’échange JSON) exposées (Bloc Api Public et Api Admin sur le schéma). Il est l’unique point d’authentification et permet de protéger plusieurs applications en utilisant les protocols OpenID connect / OAuth 2. Le système de gestion d’identité et d’accès est implémenté par Keycloak (http://www.keycloak.org/). Cet outil permet de :
- Gérer une base de données de groupes/utilisateurs
- Gérer l’authentification des différents utilisateurs
- Protéger plusieurs applications en utilisant le protocol OpenID connect en mode SSO
- Intégrer des gestionnaires d’identité tiers comme Facebook, Google, Twitter etc …
- Fédérer les utilisateurs avec d’autres fournisseurs (LDAP, Base de données etc …)
Keycloak, quant à lui, est une solution open source sous licence apache 2 (http://www.apache.org/licenses/) portée par la société RedHat (https://www.redhat.com/fr).
Appstud a souhaité mettre en place, en sus, le “[Operator] Connect” (similaire à un Facebook Connect). Notre SSO permet à des applications tierces d’utiliser la fonctionnalité «[Operator] Connect » pour récupérer les informations publiques d’un abonné afin de le connecter ou bien de lui créer un compte. Grâce à cette fonctionnalité, l’opérateur peut authentifier ses clients en un clic sur leur portail.
Clean architecture
Nous nous sommes rapidement rendu compte d’un challenge complexe pour le Backend Digital. La communication et la synchronisation des différentes sources de données, pour la plupart complètement hétérogène, allait être névralgique dans le développement, maintenabilité et la scalabilité de la solution.
Nous avons donc mis en place une architecture à base d’interfaces permettant d’isoler les différentes sources de données et les rendant complètement modulaire et changeable à tout instant sans changer la logique métier. Grâce à Spring et à son système d’injection des dépendances, nos modules sont chargés au lancement du backend sans que le code métier n’en connaisse l’implémentation.
Domaine
Contient le code, la logique et les entités métiers. Cette couche intègre aussi un jeu d’interfaces métiers qu’elle utilise mais n’implémente pas. Ces interfaces sont très explicites et retournes souvent des entités métiers. Elle ne connait pas l’existence de la couche « modules ».
Modules
Les modules connaissant l’existence de la couche « domaine ». Ils peuvent soit utiliser les services ou implémenter une interface de la couche « domaine ».
Module REST
Le module REST était en charge de mettre à disposition une API REST. Ce module valide, créer des objets métiers à partir de requêtes HTTP puis appelle la couche domaine qui implémente la logique métier. Il est aussi en charge de formater les réponses et exceptions venant du domaine pour les présenter dans un format standardisé aux clients.
La couche « domaine » ne connaissant rien de ce module, on pourrait très bien ajouter un module de communication « REST » version 2 – qui peut être complètement différent de la version 1 – ou le supprimer complètement sans avoir à intervenir sur le coeur du système.
Module(s) Compte utilisateur
L’interface métier « Compte utilisateur » est la première interface que nous avons développé. Elle décrit des fonctions simples, telles que « Récupère l’utilisateur avec l’adresse mail X » ou « Met à jour l’utilisateur Y ».
Un premier module, connecté à Keycloak, a implémenté cette interface. Il était en charge de faire cette gymnastique de transformation de compte métier <-> compte Keycloak tout en gérant les différentes erreurs potentielles.
Lorsque le moment est venu de connecter le système au CRM – Salesforce pour notre cas – l’implémentation a été triviale. Nous avons développé un module connecté à Salesforce implémentant la même interface que Keycloak, implémentant les logiques nécessaire mais pour Salesforce cette fois-ci.
Nous n’avions plus qu’à faire en sorte que notre couche domaine boucle sur tous les modules implémentant notre interface, en gérant l’ordre de priorité grâce à une énumération et une configuration simple.
Résultats
Cette modularité nous a beaucoup plus apporté que ce que nous pensions. Exit les problèmes de sources de données lors de nos tests, nous pouvions très facilement supplanter un module par un « mock » – une implémentation test autonome n’étant pas soumis à la disponibilité d’un service distant.
Aussi, chaque module pouvait être testé de manière autonome pour s’assurer que la source de données respectait bien le format attendu. Chaque source de données étant soumise à diverses évolutions lors de notre développement, nous pouvions très rapidement diagnostiquer le problème et agir sur le module sans remettre en cause nos logiques métiers ou nos autres implémentations.
Cette assurance nous à permis de garder une certaine vélocité malgré les fréquentes modifications des systèmes externes utilisés.
Moteur de Recherche
Le backend intègre un moteur de recherche permettant d’indexer des données de différentes sources hétérogènes en les rendant facilement accessible pour faire de la recherche. Nous avons fait le choix d’utiliser le moteur de recherche Elasticsearch développé par Elastic. Il stocke de façon efficace les données pour les rendre identifiables facilement.
Conjointement à Elasticsearch, nous nous sommes servis d’un autre outil développé par Elastic; Kibana. Ce dernier sert d’interface à Elasticsearch en proposant un portail web permettant de facilement trier, chercher et formaliser des graphiques ou des données contenues dans le moteur de recherche.
Un ensemble de documents supports, tels que les rubriques d’aides, sont indexés pour à termes proposer à l’utilisateur final de trouver facilement une documentation pour résoudre son problème.
Journalisation
La journalisation centralise et normalise les multiples logs générés sur les différentes couches de l’application afin de les visualiser sur une interface graphique. On en dénombre deux principalement:
- Écriture des traces facilitant la mise au point lors des développements et le diagnostic en cas d’anomalie par la suite.
- Journalisation dédiée, enregistrant des opérations particulières à surveiller ( telles que des rapport détaillant des actions purement métier ).
Dans le premier cas, en situation de production, seules des traces d’un niveau utile à l’exploitant sont produites. Les niveaux correspondant sont :
- INFO: un événement remarquable a été constaté comme le démarrage réussi d’une application
- WARN, ERROR, FATAL: une situation anormale a été diagnostiquée.
Nous avons utilisé Filebeat et Logstash pour récupérer les logs des différents applicatifs. Filebeat (produit d’Elastic) permet de récupérer les logs dans Elasticsearch. Ces logs sont ensuite visualisables à travers l’interface Kibana. Logstash est un produit d’Elastic qui récupère, traite et synchronise les logs dans Elasticsearch, provenant principalement du backend-digital.
Ces journaux, décrivant l’activité des différents services tout en enregistrant des évènements métiers provenant de notre API servent de support pour diagnostiquer les problèmes sur l’environnement de production. Les opérateurs techniques de la plateforme s’appuient sur ces journaux quand un problème est remonté par le service client ou pour des opérations de maintenance. Grâce à la souplesse d’Elasticsearch, une granularité très fine à pu être gérer au niveau des journaux API, allant d’une simple opération métier au log complet et précis d’une erreur provenant d’une source externe de données.
Grâce aux fonctionnalités de Kibana, un dashboard filtrant toutes les erreurs critiques, d’accès et de sécurité permet aussi de s’assurer en un coup d’oeil que l’environnement n’est pas compromis et qu’il fonctionne correctement.
Une solution de rotation de données a été mise en place sur les logs pour éviter de saturer la base de données Elasticsearch. Pour ce faire, nous avons utilisé un outil d’Elastic appelé Curator – que nous avons aussi « Dockerisé » et mis à disposition sur notre GitHub.
NB: Nous avons utilisé la version 6.3 d’Elasticsearch, néanmoins depuis la version 6.6, Curator n’est plus nécessaire et vous pouvez directement utiliser la fonctionnalité d’Index Lifecycle Management intégrée à Elasticsearch.
Monitoring
Le monitoring centralise les métriques produites par les différents composants de l’application et les affiche sous forme de tableau de bord personnalisable. Il permet également de paramétrer des alertes (mail) en fonction de seuil défini (par exemple : utilisation cpu > 80%).
Nous avons mis en place Metricbeat pour récupérer les métriques des applicatifs tels que Backend, Reverse Proxy ou Keycloak. Cet outil récupère les métriques dans Elasticsearch. Ces logs sont ensuite visualisables à travers l’interface Kibana.
Nous avons récupéré en priorité les données suivantes :
- Utilisation processeur
- Utilisation mémoire
- Codes HTTP retournés par l’API
- Paquets réseaux envoyés et reçus
- Espace disque utilisé
Ces données sont alors visualisables à travers un dashboard Kibana, représenté ci-dessous
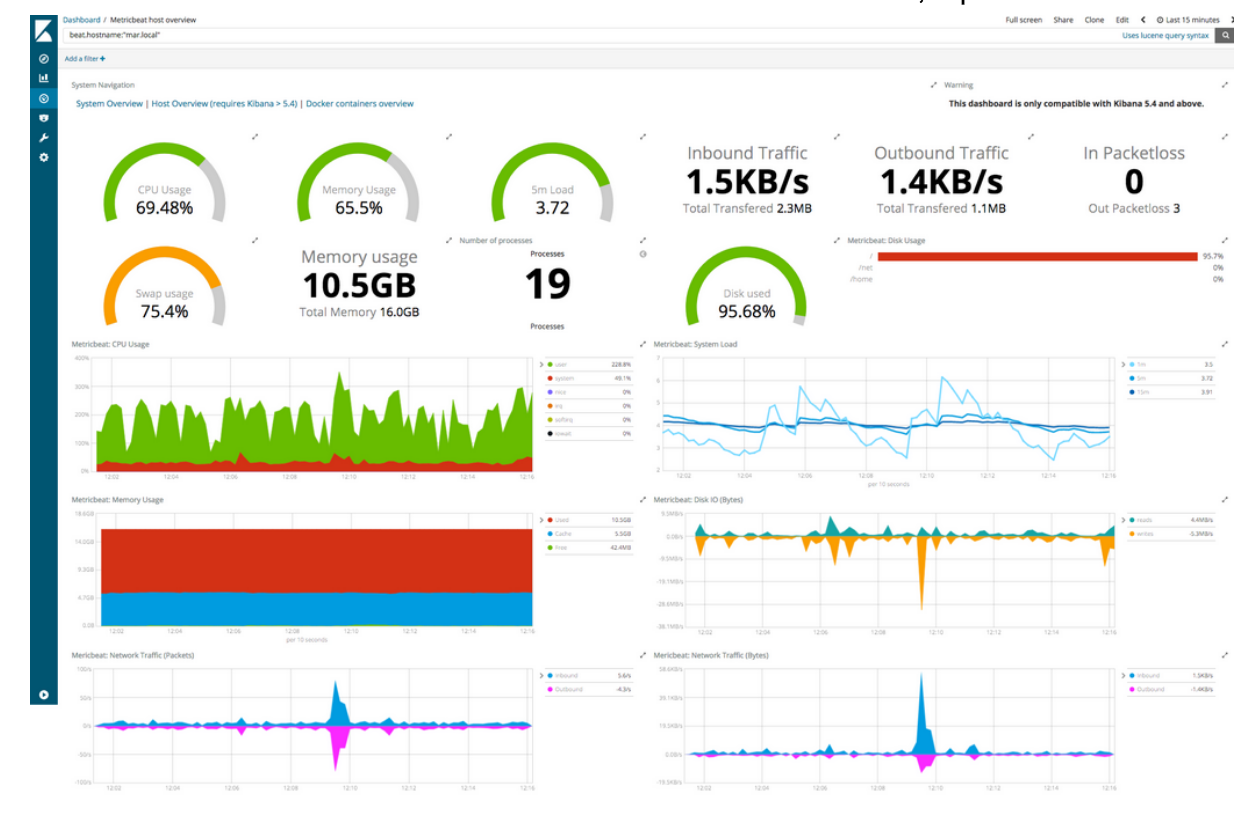
Fig 3: Visualisation de données au travers Kibana
Gestionnaire du cache
Ce module permet de mettre en cache des données afin de réduire le temps d’accès et/ou le nombre d’interconnexions entre les sources.
Il est responsable de la réplication des données entre les instances de l’application afin de garantir leur cohérence.
Chaque donnée en cache est identifiée de manière unique par un nom et pourra être relancée via une politique de réinitialisation (ex : toutes les 30mn, à chaque action spécifique etc…) ceci via une api webservice administrateur.
Pour se faire, Infinispan a été utilisée. Il s’agit d’un gestionnaire de cache libre et gratuit proposant un mode de cache répliqué (synchrone ou asynchrone) en propageant les modifications des données en cache sur toutes les instances de l’application. http://infinispan.org/docs/stable/user_guide/user_guide.html#replicated_mode
Tests de performance
En sachant que le trafic serait intense sur les premières semaines du lancement, il était important de nous assurer de la scalabilité et de la résilience de notre système. Pour cette raison, nous avons mis en place des tests de performance qui ont été réalisés avec l’outil JMeter (https://jmeter.apache.org/).
Des scénarios d’utilisation représentatifs ont été créés (enchaînement d’actions utilisateurs) et joués sur l’application. Les résultats de ces tests nous ont permis de connaître notre capacité de traitement (requêtes / secondes) d’une ou plusieurs instances de l’application. Nous avons ainsi eu la possibilité de dimensionner les infrastructures pour l’environnement de production.
Les applications mobiles
Pour la qualité du produit final et son évolution, il ne faisait aucun doute que les technologies de développement natives devraient être utilisées. L’application devait être en mode portrait peu importe le terminal et il ne nous a pas été demandé de déclinaison tablette. Elle devait pouvoir être internationalisée pour le français, l’arabe et l’anglais. Nous avons ainsi dû prendre en compte l’affichage “RTL” (Right to Left) pour l’arabe.
Android
Nous sommes partis sur un développement natif en Kotlin avec le SDK Android (version 5.0 API 21 minimum) en utilisant l’IDE Android Studio.
Nous avons utilisé Gradle pour la gestion des dépendances et ces quelques bibliothèques éprouvées open source :
- Retrofit (https://github.com/square/retrofit) : pour faire les appels HTTP vers les différentes API
- Picasso (https://github.com/square/picasso) : pour télécharger les medias avec gestion du cache
- Logger (https://github.com/orhanobut/logger) : gestion des logs
Ce projet a utilisé le pattern Android Architecture ViewModels (documentation officielle : https://developer.android.com/topic/libraries/architecture/viewmodel?authuser=1).
Cette architecture permet de séparer la logique métier (récupération de données de l’API, calcul de certains résultats) du code de l’interface utilisateur (couleurs, mise en forme, animations). Elle permet également de garder des données persistantes sur des fragments sous la même activité.
iOS
Le développement natif a été réalisé en Swift 4.* avec l’IDE Xcode version 9.*. La version minimum cible d’iOS était iOS 10.*. Nous avons utilisé cocoapods pour gérer les dépendances, voici quelques bibliothèques utilisées :
- Alamofire (https://github.com/Alamofire/Alamofire) : pour faire les appels HTTP vers les différentes API
- Kingfisher (https://github.com/onevcat/Kingfisher) : pour télécharger les medias avec gestion du cache
- CocoaLumberjack (https://github.com/CocoaLumberjack) : gestion des logs
Le pattern utilisé pour le projet iOS était VIPER (View, Interactor, Presenter, Entity, Router). Cette architecture basée sur le principe de responsabilité unique garantit une “clean architecture”.
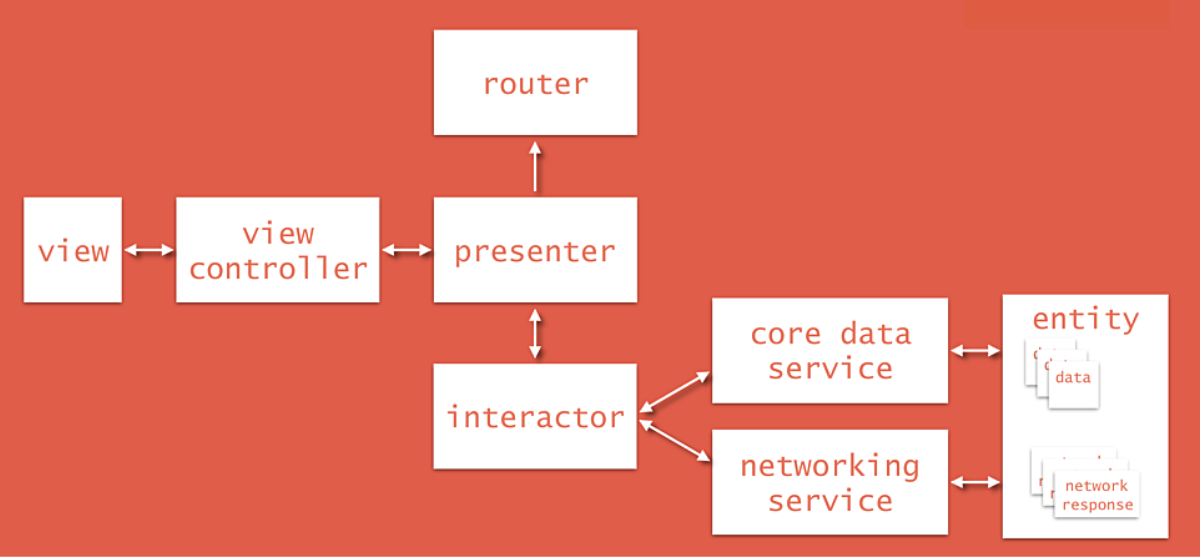
Fig 4. Clean Architecture
View : envoie les actions de l’utilisateur au “Presenter” et affiche ce qu’il lui dit d’afficher.
Interactor : épine dorsale d’une application qui contient la logique métier.
Presenter : obtient les données de l’”Interactor” sur les actions de l’utilisateur. Après avoir obtenu les données de l’”Interactor”, il les envoie à la “View” pour les afficher. Il demande également au “Router” de naviguer entre les différents écrans de l’application.
Entity : contient les objets de modèle de base utilisés par l’”Interactor”.
Router : renferme toute la logique de navigation décrivant quel écran doit être affiché à quel moment.
Les protocoles sont utilisés pour communiquer entre les différentes couches. Cette architecture génère beaucoup de fichiers ce qui a facilité la collaboration à plus de 3 développeurs. Nous conseillons fortement VIPER si vous êtes au moins de 2 développeurs sur un même projet.
WebApp
La WebApp (nom du site internet) a été développé avec le framework VueJS et NuxtJS (https://nuxtjs.org/). Ce framework facilite la création et le déploiement d’applications isomorphiques avec Vue.js. NuxtJS est l’équivalent de Next.js pour React ou Angular Universal pour Angular.
La WebApp devait être responsive pour le mode tablette, smartphone et desktop. Le site devait être consultable sur des écrans entre 320px et 1920px.
Notre objectif était de rendre le site parfaitement fonctionnel sur :
- Chrome – version 61.* min
- Safari – version 10.* min
- Firefox – version 56.* min
- Edge – version 41.* min
- Internet Explorer – version 11.* min
Comme pour les applications mobiles, le site devait être internationalisé pour le français, anglais et arabe, donc gestion du “Right to Left”.
La solution technique devait aussi permettre un très bon référencement SEO tout en gardant une bonne expérience utilisateur avec une navigation ultra rapide.
Notre choix s’est porté sur Vue.JS et Nuxt.JS qui permettent, grâce à une première génération côté serveur, de garder un très bon référencement avant de basculer sur le fonctionnement du web-app classique sans que l’équipe n’ait eu à se soucier de la configuration où changer sa manière de développer.
CMS et Back Office
Le client souhaitait gérer son catalogue dynamiquement aussi la mise en place d’un CMS était une évidence. Nous avons fait le choix de travailler avec Drupal 8 qui met à disposition tous les outils pour créer et administrer des contenus. Drupal 8 pourrait ainsi jouer le rôle de back-office du site internet et des applications mobiles.
Le CMS Drupal enrichit les produits du catalogue Telco édités depuis Salesforce (https://www.salesforce.com/). Quand le backend digital récupère les données sont brutes, il n’y a aucune image ou accroche marketing associées aux produits du catalogue. Le CMS intervient donc à ce moment pour enrichir les produits du catalogue pour les interfaces clients (applications mobiles, site internet).
Comment cela fonctionne ? Le backend digital utilise l’API Drupal pour y insérer le catalogue Telco brut. Par la suite, depuis l’interface d’administration Drupal, des administrateurs peuvent enrichir ces données par des visuels et du contenu texte.
Un système de “hook” est mis en place entre le backend digital et Drupal pour que le backend digital vienne récupérer du Drupal les données enrichies afin de les mettre en cache puis de les exposer aux interfaces clients au travers son API RESTful.
Il existe aussi un “hook” entre Salesforce et notre backend-digital permettant à Salesforce de nous avertir quand une nouvelle version du catalogue Telco vient d’être publiée.
Ci-dessous un schéma pour expliquer le processus :

Fig 5. CMS et Back Office
Intégration continue
Pour éviter les régressions et fluidifier les déploiements, il était nécessaire de mettre en place des plateformes d’intégration continue. Ces plateformes ont permis l’automatisation des tâches : compilation, tests unitaires, tests d’intégrations, tests fonctionnels, validation produit, tests de performances. Ainsi, à chaque changement du code, l’équipe recevait un ensemble de résultats qu’elle pouvait alors consulter pour s’assurer de l’intégrité du projet. Cette intégration aide à ne pas oublier d’éléments lors de la mise en production et ainsi à améliorer la qualité du produit.
Pour automatiser la compilation et les déploiements du backend de la webApp et du CMS Drupal, nous avons combiné les solutions Jenkins et Docker.
Android était connecté à notre Jenkins et nous utilisions Fabric pour envoyer des versions OTA (Over the air) de l’application au client.
iOS, quand à lui, était connecté à BuddyBuild (solution rachetée par Apple), une plateforme d’intégration continue spécialisée pour iOS permettant aussi le déploiement OTA des versions.
Le développement
Compte tenu de l’échéance courte, la phase de développement s’est déroulée en 6 sprints de 4 semaines. Les équipes web et mobile se sont appuyées sur plusieurs documents/outils pour avancer :
- une spécification fonctionnelle détaillée sur Google Docs dont l’objectif était d’expliquer les parcours et toutes les règles métiers
- un fichier Sketch contenant l’ensemble des maquettes à intégrer
- un JPEG storyboard qui donnait la vision d’ensemble du projet côté “interface”, document très utile pour comprendre les connexions entre les différents écrans.
- La documentation en ligne de l’API du backend digital était auto générée à chaque nouvelle compilation par la plateforme d’intégration continue. Cette documentation mettait aussi à disposition un projet Postman, très pratique pour les équipes.
- Un projet JIRA permettant de prioriser/affecter les tâches, de suivre la progression et de mettre en exergue les points bloquants.
- Plusieurs channels Slack pour fluidifier les échanges entre les développeurs frontend, backend et la gestion de projet.
Au niveau des équipes backend, l’exercice fut bien plus compliqué car ils devaient s’interfacer avec l’ensemble des services tiers, à savoir Salesforce et les systèmes du Legacy utiles. De nombreux ateliers en Afrique ont été nécessaires pour coordonner les différents acteurs.
La principale problématique que nous avons rencontrée était de devoir exposer une API aux frontend en utilisant des services qui étaient eux aussi en plein “Build” par des équipes tiers. La conséquence a été d’avoir sur les 4 premiers sprints une API du backend-digital instable ou assez peu avancée. Les équipes frontend ont, quand à elles, dû continuer à développer des parcours en mode bouchonné (c’est à dire sans utiliser l’API). Il a donc été très compliqué de s’interfacer avec des API en plein “Build” car il était fréquent qu’une interface côté Salesforce change du jour au lendemain, ce qui avait pour effet de rendre indisponible des services de notre API.
Ce fonctionnement nous a obligé à développer des tests d’intégration que nous faisions tourner jusqu’à 3 fois par jour afin de nous assurer qu’il n’y avait pas de régression côté Salesforce ou du Legacy client. Ces tests nous ont fait gagner énormément de temps d’investigation puisque quand les équipes frontend remontaient une anomalie sur l’API du backend digital, nous pouvions rapidement voir si celle-ci provenait d’une régression du côté prestataire externe.
Ci dessous, un exemple de notre rapport d’intégration continue accessible en ligne pour l’ensemble des intervenants sur le projet :

Fig 6. Rapport Intégration continue
Les résultats
Pour démarrer la phase de test, une équipe de testeurs à temps plein a été mobilisée pendant 2 mois. Une fois cette phase terminée, les applications et le site ont été mis à disposition des équipes Métier du client.
En 2 mois d’activité, il a été dénombré 42 000 utilisateurs actifs sur Android contre 5 000 sur iOS et plus de 100 000 sessions enregistrées (données firebase).
Sur la version Android 98,74% des utilisateurs n’ont subi aucun plantage contre 99,17% sur la version iOS.